Deep Think with Confidence

- LLM은 뭐? 자신감~~
- 논문
- Fu & Zhao et al., Aug 21 2025, Meta AI & UCSD
요약
- test-time scaling에 따라서 여러번 돌리면 성능은 올라갔는데, 불안정하고 컴퓨팅 자원도 많이 소모됨.
- 논문은 reasoning 중 모델의 자신감을 측정해서 각각 reasoning path를 필터링함.
- 이 자신감 측정기를 이용해서 모델의 성능은 올리고, 생성하는 토큰의 수는 훨씬 줄어들게 함.
기존 방법 : self-consistency with majority voting
-
높은 temperature로 여러 번 각기 다른 reasoning path로 답변을 생성한다
-
여러 개의 답변들에서 정답을 추출한다.
-
가장 많이 나온 정답을 최종 정답으로 정한다.
-
이렇게 하면 성능은 꽤나 올라가는데, 당연히 너무 많은 인퍼런스가 필요해서 컴퓨팅 자원이 많이 소모된다.
-
ex) Qwen3-8B에서 AIME 2025 성능을 68% => 82% 올리는 데에 약 1억 토큰이 더 소모된다.
-
모든 reasoning path를 퀄리티와 상관 없이 동일하게 중요하다고 생각하기에, 성능이 떨어져 버릴 때도 있다.
LLM의 자신감 측정법

토큰 엔트로피
번째 토큰을 생성할 때 토큰의 분포 - 토큰 엔트로피 - j번째 보캡의 토큰이 나올 확률
즉, j 토큰분포의 정보량을 의미한다. (참고) 작은 엔트로피는 특정 토큰에 대해 모델이 더 집중된 (높은) 분포를 보였다는 것이고, 높은 엔트로피는 여러 토큰들에 대해 불확실성이 높았다는 것이다.
토큰 자신감 (Token Confidence)
- 토큰 자신감
는 번째 토큰 생성에 있어 top-k개의 negative log-probability의 평균이다. - 그러므로, 토큰 자신감이 높다는 것은 소수의 토큰들의 생성 확률이 높았다는 것이다.
- 반대로, 토큰 자신감이 낮다는 것은 가장 확률이 높은 토큰들도 그다지 확신하며 생성하지 않았다는 것이다.
- 위와 같이 모든 생성된 토큰에 대해서 토큰 자신감을 계산하고, 평균을 때려서 평균 토큰 자신감을 계산했다.
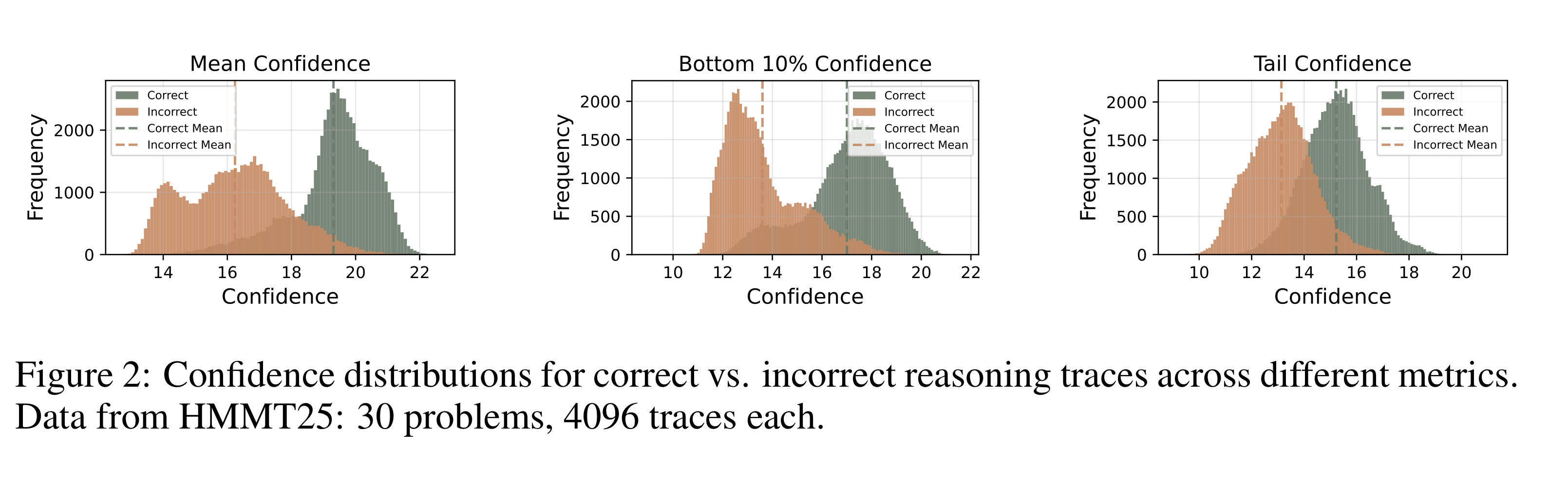
-
실제로 실험을 해보니, 정답이 correct (녹색)인 경우에 incorrect (주황색)인 경우보다 더 높은 자신감을 가지고 있는 것으로 나타났다.
-
근데 위처럼 평균을 치면, 평균의 오류가 생길 수 있다. 몇 개 토큰만 엄청 높은 confidence를 가지면 낮은 여러 토큰들의 영향을 지워버릴 수 있는 것이다. 그리고 reasoning path 전체를 모두 구해야 하기 때문에, 이미 퀄리티가 낮은 reasoning의 early stopping이 불가하다.
DeepConf (논문이 제안한 방법)
- offline thinking : 다 reasoning을 한 다음 그 자신감 정보로 답변 성능을 개선한다.
- online thinking : reasoning 중간에 자신감 정보를 활용한다.

여러 자신감 계산 방법들
-
전체 평균 말고 다른 방식으로 자신감을 계산해서, 전체 평균의 취약점을 보강하고자 한다.
-
그룹 자신감 : sliding window 방식을 이용해서
개의 전 토큰들까지만 자신감을 평균 내서 사용한다. -
중간에 갑자기 자신감이 떨어지면 보통 답변이 안 좋게 나오는 현상을 관찰해서, 이런 그룹 자신감이 효과적이다.
-
하위 10% 그룹 자신감 (a.k.a 8등급 자신감) : 그룹 내의 하위 10% 자신감만 평균낸 수치다.
-
꼬리 자신감 (Tail Confidence) : reasoning path 끝쪽
개의 토큰만 평균낸 수치. -
대체로 reasoning 문제에서는 마지막 결론 도출 과정이 중요하다.
Offline Thinking
- 평범한 majority voting : 여러 reasoning path의 답들 중 가장 많이 나온 답을 고른다.
- Confidence-Weighted Majority Voting : 그냥 다 똑같이 생각하지 않고, 자신감을 가중치로 줘서 자신감이 높은 reasoning path에서 나온 답을 더 높은 가중치로 쳐준다.
- 자신감 필터링 : 실제 정답 도출에 자신감이 top-
% 이상인 것들만 고려했다.
Online Thinking
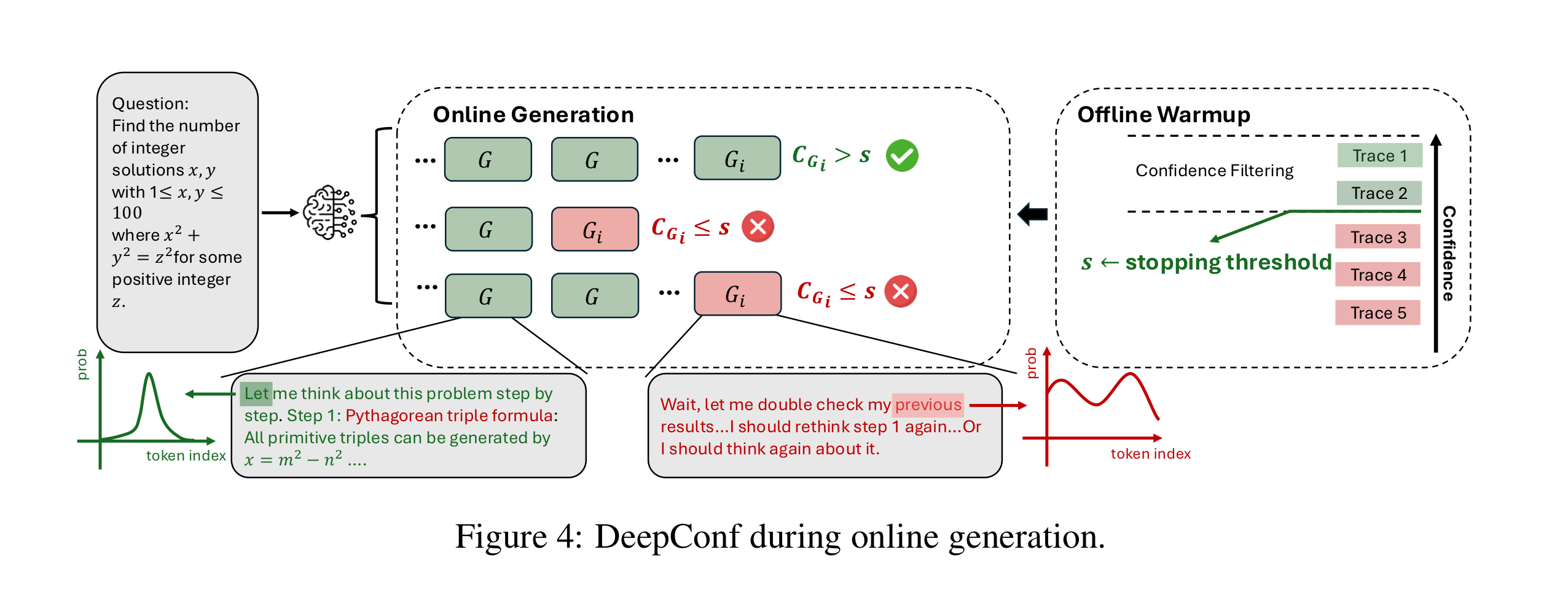
- 그룹 자신감 수치에 따라서 자신감이 너무 낮으면 reasoning 중간에 인퍼런스를 중단한다.
1. Offline Warmup
- stopping threshold를 정하기 위해서 먼저 offline warmup을 해야 한다.
- 16개 정도의 적은 양의 full reasoning trace를 생성한다.
- 이것들 중 top-
% 구간이 threshold가 된다. - Deepconf-low는 top-10% 구간만 사용하고, Deepconf-high는 top-90% 구간까지 사용한다.
- 이 threshold 아래로 생성 중에 자신감이 내려가면 인퍼런스를 중단해버린다.
2. Adaptive Sampling
- 전체 vote 대비 majority voting을 받은 답변이 특정 임계점 이상을 넘길 정도로 충분히 클 때까지, 새로운 reasoning trace를 생성한다.
-
- 선정된 답 -
- 그것의 voting score (weighted by confidence) -
- 모든 답 후보들 -
해당
값이 특정 threshold를 넘을 때 최종 답변을 내뱉는다.
실험
실험 대상
- Pass@1 - 한 번만 돌렸을 때
- Cons@K - unweighted majority voting
- Measure@K - confidence-weighted majority voting (자신감 사용)
- Measure+top-
%@K - 상위 %의 자신감만 사용한 경우 - DeepConf-low, DeepConf-high - online evaluation
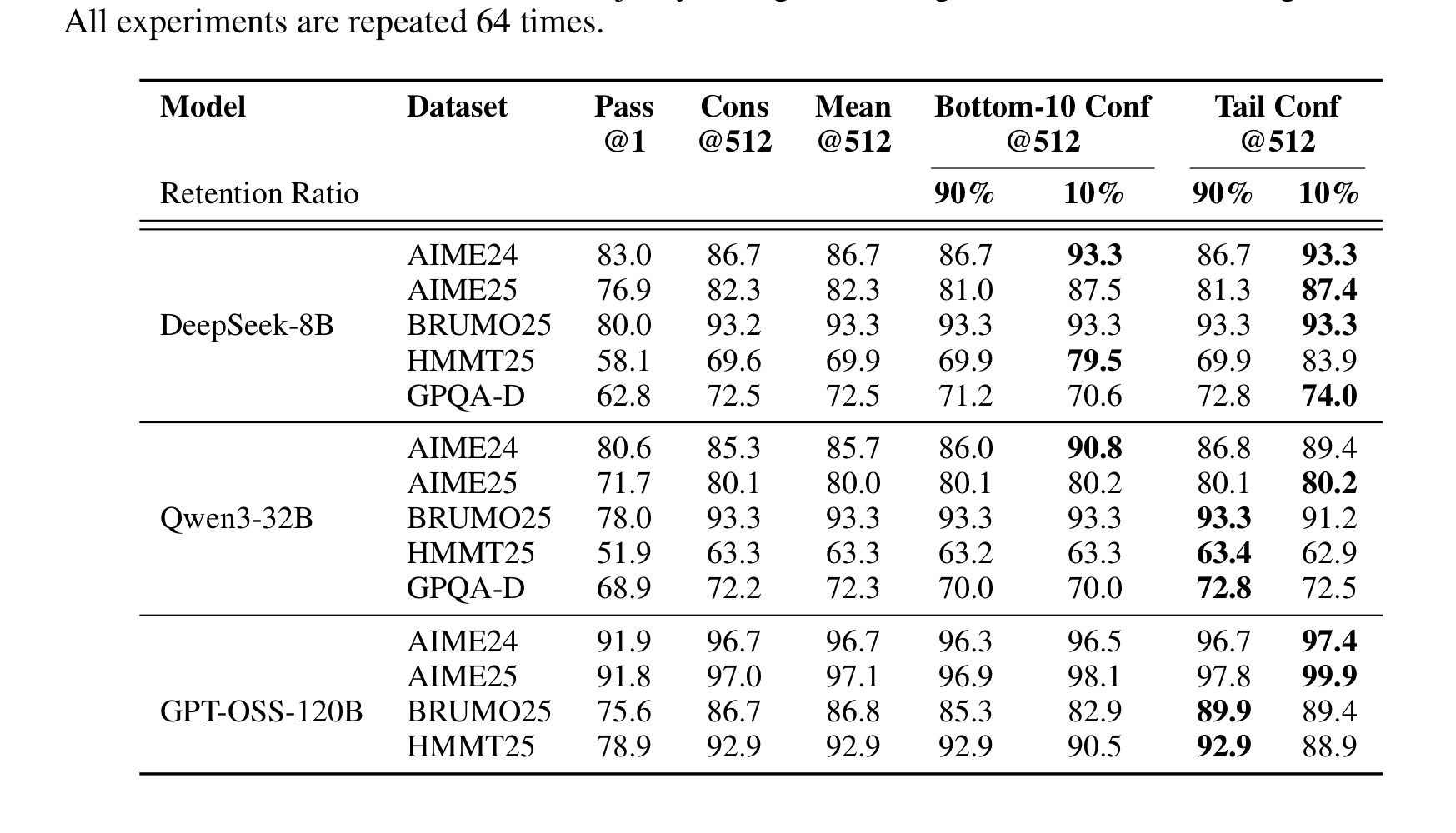
오프라인 결과
온라인 결과
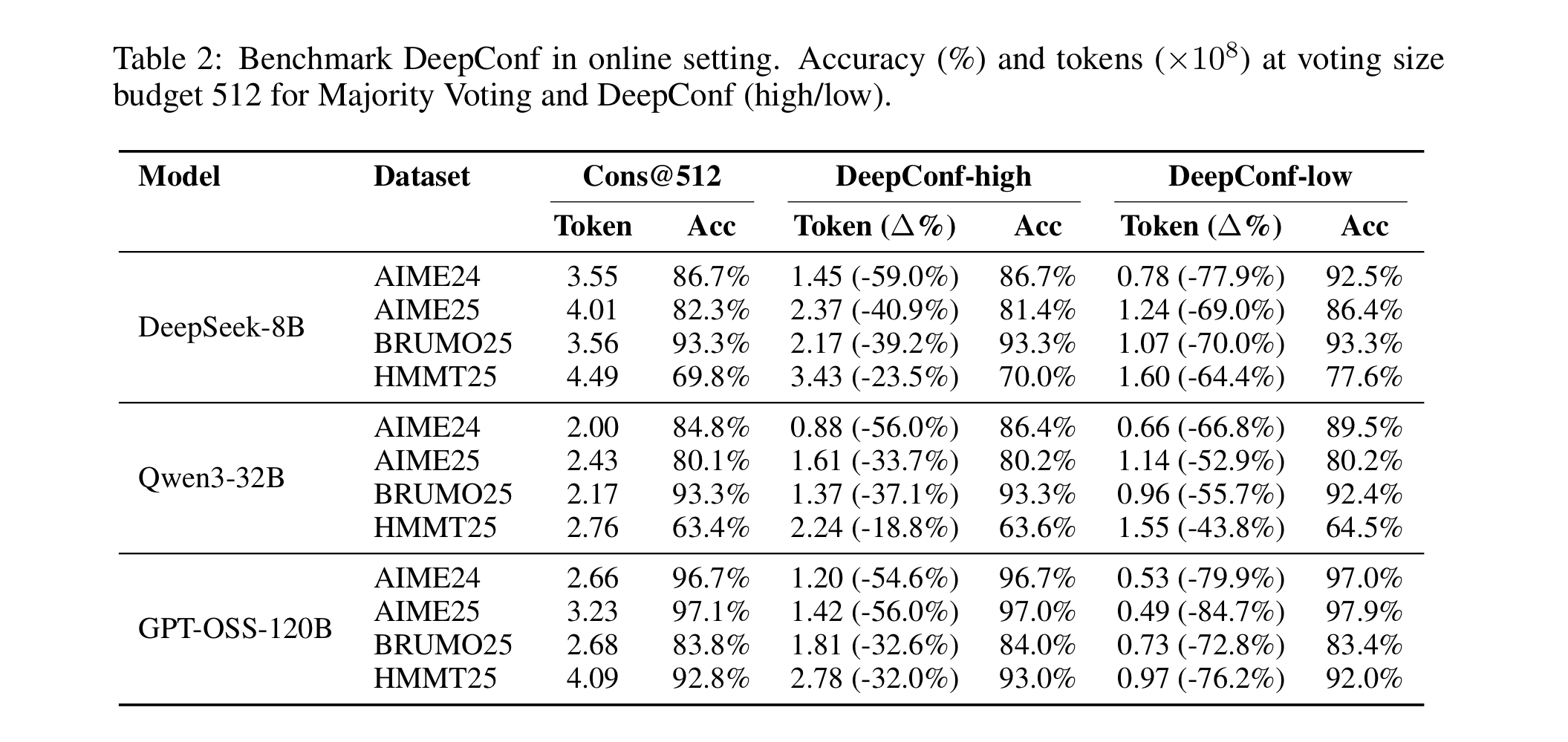
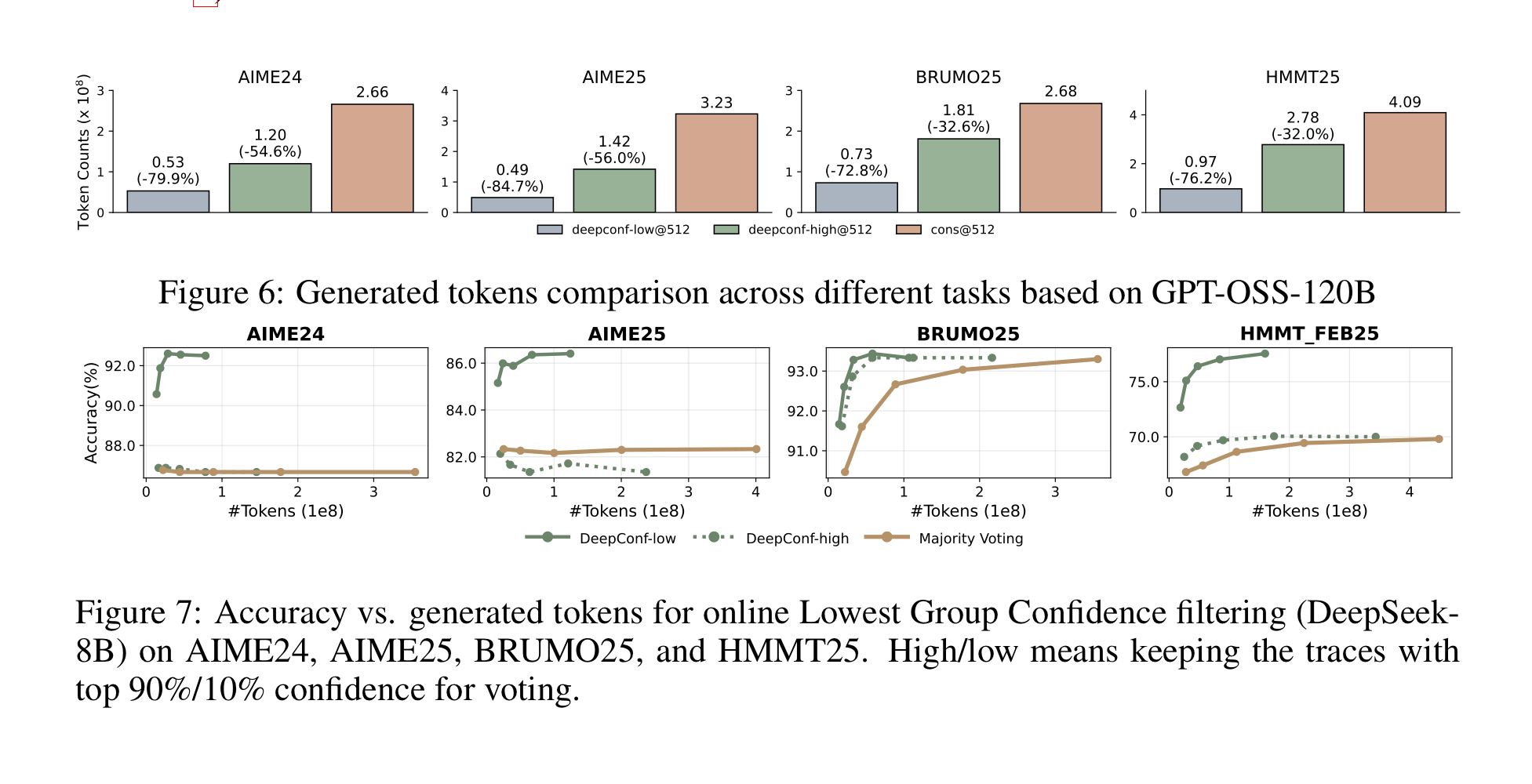
온라인으로 하니 성능은 유지되거나 높아지면서, 토큰은 훨씬 덜 생성했다!
결론
- LLM의 internal signal에서 자신감 요소를 정의하고, 그것을 이용해 보다 효율적인 test-time scaling을 해냈다.
- 돈과 시간만 있다면 LLM이 더 더 어려운 문제를 풀 수 있다! 근데 돈을 아끼려면 자신있는 풀이만 풀게 하자.